

TL;DR
- The gist: The Allen Institute for AI (AI2) has released Bolmo, a new family of byte-level language models created by retrofitting existing OLMo 3 models instead of training from scratch.
- Key details: Bolmo 7B outperforms Meta’s BLT 7B by 16.5% on STEM tasks and used less than 1% of the typical pretraining compute budget.
- Why it matters: This “byteification” process allows organizations to convert standard LLMs into tokenizer-free models cheaply, eliminating errors with rare words and multilingual text.
- Context: While highly efficient, Bolmo slightly trails subword models in generation speed (125 vs 150 bytes/s).
Bypassing the prohibitive costs of training novel architectures from scratch, the Allen Institute for AI (AI2) has introduced Bolmo, a new family of language models that process raw bytes instead of tokens. By “byteifying” its existing OLMo 3 models, reusing the backbone and capabilities already invested in, the institute achieved state-of-the-art character understanding using less than 1% of the original pretraining compute budget.
Released Monday under the Apache 2.0 license, Bolmo 7B outperforms Meta’s competing Byte Latent Transformer (BLT) by 16.5% on STEM tasks. This retrofit approach offers a viable path to eliminate “tokenization bias” (errors caused by rigid vocabulary lists) without the substantial investment previously required to train tokenizer-free systems.
Building on the “Model Flow” strategy established with the OLMo 3 launch, AI2 released full weights, code, and the Bolmo Mix dataset. The release proves that standard Large Language Models (LLMs) can be converted to byte-level architectures post-training, preserving their reasoning capabilities while gaining granular control over text processing.
Promo
The ‘Byteification’ Shortcut: Architecture & Economics
Rather than discarding the significant investment required to train a foundation model, AI2’s researchers developed a method to retrofit existing architectures. “Byteification” converts a standard subword model, specifically the OLMo 3 architecture, into a byte-level system by replacing its input and output layers while retaining the deep transformer backbone.
Central to this efficiency is the dramatic reduction in required compute. Training a competitive byte-level model from scratch typically requires trillions of tokens. In contrast, the Bolmo process utilizes approximately 9.8 billion tokens for the initial distillation phase (Stage 1) and 39.3 billion tokens for the end-to-end training phase (Stage 2).
Representing a fraction of the cost, the total amounts to less than 1% of the typical pretraining budget for a model of this class.
Standard Large Language Models (LLMs) rely on a fixed vocabulary of 30,000 to 300,000 subword tokens, a design choice that often introduces rigidity. Bolmo replaces this with a fixed vocabulary of just 256 UTF-8 bytes. By processing text at this granular level, the model avoids the “vocabulary bottleneck” that limits performance in multilingual contexts or with rare words.
To make this conversion work without degrading performance, the architecture introduces a “non-causal boundary predictor.” Unlike traditional autoregressive models that only look backward, this component utilizes one byte of future context during the prefill stage.
Looking ahead by just one step allows the model to mimic the boundary placement of efficient subword tokenizers. This effectively matches their compression rates while retaining the flexibility of byte-level processing.
The technical report defines the scope of this innovation:
“In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs.”
“Byteification enables overcoming the limitations of subword tokenization, such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary, while performing at the level of leading subword-level LMs.”
To ensure stability, the training process executes in two distinct phases. Stage 1 freezes the global model parameters, training only the new local encoder and decoder components to mimic the behavior of the original subword model.
Once the new components are aligned, Stage 2 unfreezes the entire network, allowing the global model to adapt to the richer byte-level information.
Addressing the balance between efficiency and granularity, researchers at AI2 highlight that this method solves long-standing trade-offs in model design:
“Byteification enables overcoming the limitations of subword tokenization… while performing at the level of leading subword-level LMs.”
Benchmark Reality: Bolmo vs. The Field
While efficiency is the primary breakthrough, the resulting performance metrics suggest the architecture punches above its weight. Bolmo 7B, with 7.63 billion parameters, achieves a +16.5% absolute improvement in STEM tasks compared to Meta’s Byte Latent Transformer (BLT) 7B, which was trained from scratch.
Character mastery represents the most significant advantage of this architecture. On the CUTE (Character Understanding) benchmark, Bolmo 7B scored 78.6, vastly outperforming its own parent model, OLMo 3 7B, which scored 56.9.
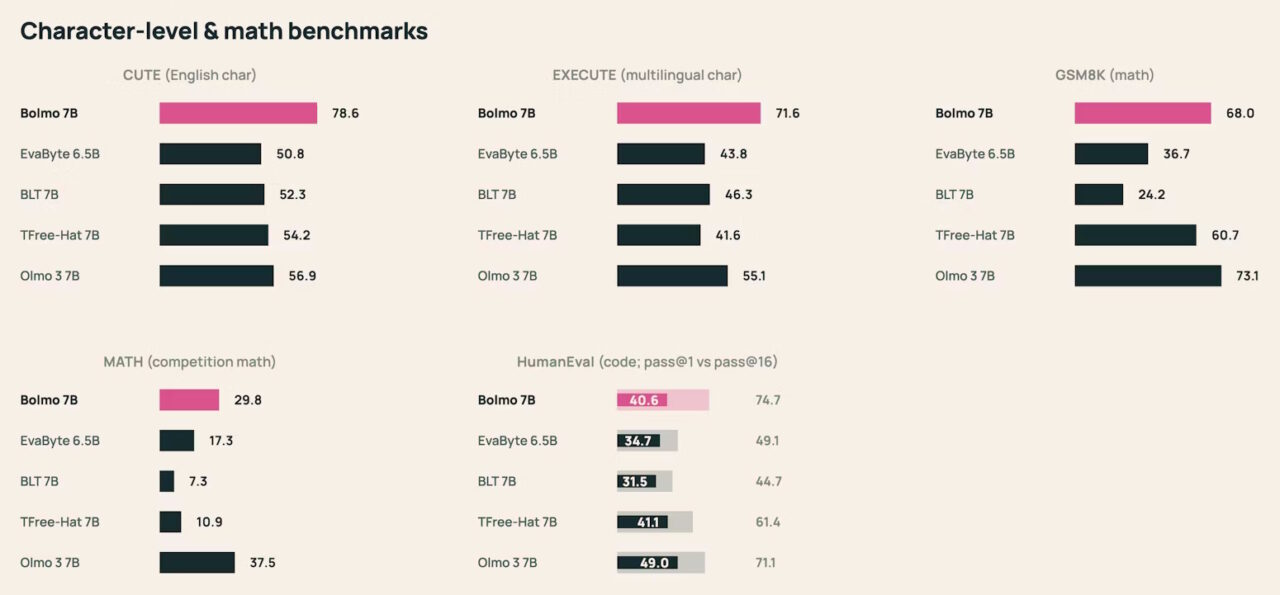
Such precision is critical for tasks requiring precise spelling, anagram solving, or code generation where single-character accuracy matters.
Subword tokenization has long been a necessary evil in NLP, trading granularity for computational speed. However, this compromise introduces subtle errors, known as tokenization bias, where the model struggles with prompts ending in whitespace or partial words.
AI2 details how these artifacts degrade model reliability:
“Subword tokenization has been remarkably successful, but it comes with real costs: poor character-level understanding, awkward behavior around whitespace and rare words, and a rigid vocabulary.”
Despite these gains, the shift to bytes introduces a slight penalty in raw generation speed. Bolmo achieves a decoding speed of approximately 125 bytes per second, trailing the subword baseline of roughly 150 bytes per second.
Increased processing steps required for raw bytes cause this reduction, though the gap is significantly narrower than in previous byte-level attempts.

For developers, the trade-off between speed and precision may depend on the specific application. The researchers suggest that for many use cases, the gap is negligible:
“Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.”
The release includes two distinct model sizes to serve different compute envelopes. Bolmo 7B is derived from the OLMo 3 7B base, while the smaller Bolmo 1B (1.47 billion parameters) is based on the older OLMo 2 1B architecture. Both models demonstrate that the “byteification” process is repeatable across different model generations and sizes.
Ecosystem Integration: The ‘Model Flow’ Advantage
Connecting this release to its broader open-source strategy, AI2 has ensured Bolmo fits into the existing “Model Flow” paradigm. Emphasized during the OLMo 3 launch, this concept prioritizes the transparency of the entire development pipeline over merely dumping frozen model weights.
A key feature of this integration is the support for “Task Arithmetic.” Because Bolmo retains the global transformer backbone of its parent model, it can inherit capabilities from other versions of OLMo 3.
For instance, instruction-tuning weights from a post-trained OLMo 3 model can be merged directly into Bolmo without requiring a second round of expensive training.
Lowering the barrier for adoption, this zero-cost transfer capability allows developers to utilize the robust reasoning capabilities of the OLMo 3 ecosystem while gaining the granular control of a byte-level architecture.
To facilitate immediate research and deployment, AI2 has released all artifacts under the permissive Apache 2.0 license. This includes the model weights on Hugging Face, the GitHub repository containing the training code, and the Bolmo Mix dataset used for the retrofit process.
Market Context & Adoption Hurdles
Byte-level models have historically been viewed as academic curiosities, struggling with prohibitive inference latency and training costs.
By removing the “Softmax Bottleneck” (the computational cost of predicting the next token from an extensive vocabulary), Bolmo offers better scaling efficiency for large-context applications.
Competitors like Meta’s Byte Latent Transformer have validated the performance potential of tokenizer-free architectures but required training from scratch.
Bolmo’s retrofitting approach fundamentally changes the economics. It allows any organization with a high-quality subword model to convert it to a byte-level system for a fraction of the cost.
Contrasting with AI2’s privacy-focused initiatives, such as the privacy-first FlexOlmo model which utilized a Mixture-of-Experts architecture to secure data collaboration, Bolmo targets the fundamental mechanics of how models process language.
Despite the technical achievements, adoption faces significant inertia. The entire NLP ecosystem, from training libraries to inference engines, is optimized for Byte Pair Encoding (BPE) tokenizers.
Furthermore, while AI2 has provided extensive internal benchmarks, independent analyst validation of the efficiency claims remains limited, creating a “source diversity gap” that early adopters will need to navigate.
